


In today’s digital landscape, managing incidents with speed and precision is more critical than ever. Traditionally, incident management has been a manual, reactive process: waiting for a failure, logging the error, and assigning a technician. This method is not only time-consuming but also prone to human error; as IT infrastructure becomes more complex, the volume of issues can quickly overwhelm operational teams.
A modern approach requires a shift toward autonomous resolution, where systems detect and correct problems before the end-user even notices a disruption.
Understanding Autonomous Resolution in Modern IT Operations
What is Autonomous Resolution?
It is the process of using Artificial Intelligence (AI) and Machine Learning (ML) to detect, diagnose, and resolve incidents with minimal human intervention. This is not about basic scripts; it is an advanced approach that leverages AI to monitor systems continuously, identify anomalies, and predict potential issues.
But AI alone is not enough.
Before systems can resolve incidents autonomously, they must first understand infrastructure relationships, event patterns, and business impact. That foundation is built through IT Operations Management.
ITOM: The Backbone of Operational Intelligence
Autonomous resolution begins with visibility.
IT Operations Management (ITOM) provides end-to-end observability across infrastructure, applications, and services. It collects telemetry data, events, metrics, and configuration information, creating a unified operational layer where signals can be interpreted intelligently.

This visual represents the holistic nature of ITOM: interconnected systems feeding data into a centralized operational intelligence layer. Without this structural visibility, automation is blind. With it, correlation becomes possible, and prediction becomes realistic.
ITOM is not just monitoring, it is the architectural backbone that enables intelligent decision-making across complex ecosystems.
The ServiceNow AIOps Framework: A Path to Self-Healing
To navigate the journey toward self-healing, we use a structured, data-driven framework. This allows us to move from a reactive, person-dependent response to a proactive, automated one. This practical AIOps framework classifies capabilities into three distinct categories:
Visibility and Context
In this phase, incidents are typically reported by individuals to the Service Desk, which assesses the extent of the impact and determines the priority. Here, we begin introducing diverse data points—such as user type, timing, location, and specific application context—to intelligently correlate information and automate fields previously handled manually, including priority levels, impact estimation, and resolution team assignment.
Once a problem is resolved, we analyze the root cause. If a systematic issue is identified, we trigger process improvements to transition the service into the next framework category: Analysis and Correlation.
Example: A hospital professional notices the appointment management application has stopped working on a Monday at 9:00 AM. When the user contacts the Service Desk and an incident is created, AIOps automatically assigns the correct resolution group and a P1 priority because the operating window indicates a high-impact event. Subsequent root cause analysis identifies a spike in database connections that the system was unable to handle.
Analysis and Correlation
This category leverages ITOM to filter monitoring noise, grouping related events and discarding those that do not require an alert. We then generate actionable incidents through advanced event correlation, pattern recognition, and anomaly detection.
The objective of this phase is to provide AIOps with the capacity to understand the precise impact of infrastructure issues on critical services and end-users, often detecting failures before they have even been reported. While resolution remains manual at this stage, the system actively identifies which common or repetitive problems are the best candidates for the final phase of automation.
Example: ITOM monitors the hospital’s appointment management database and detects emerging anomalies, such as transaction response times exceeding thresholds and CPU utilization reaching 80%. The system automatically generates a cataloged incident for the responsible resolution group, linking it directly to the detected anomalies to provide immediate technical context.
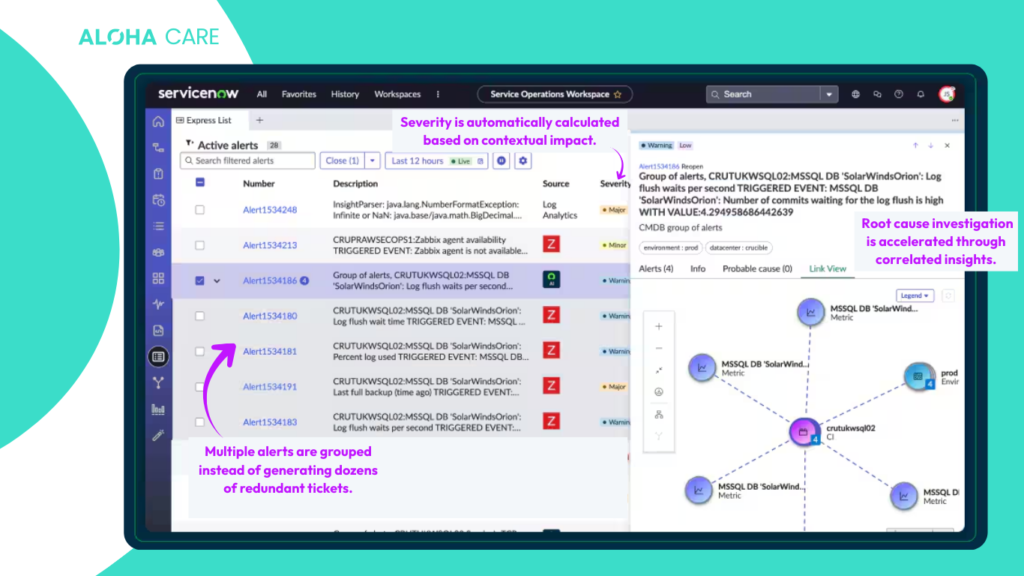
From Noise to Contextual Intelligence
Below, we can see an example of how ServiceNow’s Predictive AIOps consolidates multiple alerts into a structured, contextualized view. Instead of isolated events, the system presents correlated alerts, severity levels, and a topology map that visually connects infrastructure components to business services.
This shift from fragmented monitoring to contextual intelligence is what enables smarter incident creation and prepares the foundation for autonomous remediation.
Predict and Prevent (Self-healing)
In this final category, we implement the complete AIOps lifecycle. ServiceNow utilizes machine learning to identify subtle anomalies and proactively execute fully automated remediation actions. The goal is for the impact on end-users to approach zero; in many cases, the incident is resolved before the user is even aware that a potential problem existed.
Example: ServiceNow detects that the appointment management application is beginning to experience a high volume of activity due to a peak in usage intensity. Once the anomaly is identified, a standardized incident triggers an automated workflow that temporarily scales up database resources and restarts the frontend caching service. The responsible group receives the incident for final verification and checking only after the resolution is already complete.
About the author
Dani Martínez
Dani brings over 15 years of high-level IT expertise to our boutique practice. With a distinguished background leading ServiceNow strategies at major firms like Hiberus (Head of ServiceNow Spain) and DXC Technology, he is a proven authority in complex architectures and integrations.
A certified expert (CIS-Discovery, CSA) known for his proactive leadership and deep technical vision, Dani is dedicated to bridging the gap between complex technology and business needs.
At Aloha Clouds, he ensures every client receives the senior-level attention and strategic clarity required to turn operational challenges into seamless, autonomous solutions.

Ready to design your autonomous future?
Moving from reactive noise to proactive clarity doesn’t happen overnight, but it starts with the right strategy. At Aloha Clouds, we provide the senior expertise needed to turn the promise of AIOps into operational reality.

FAQs About AIOps
ServiceNow AIOps (Artificial Intelligence for IT Operations) is the intelligent layer of the Now Platform that uses machine learning and data science to automate how IT teams manage complex environments.
It works by ingesting vast amounts of data—logs, metrics, and events—from your entire infrastructure. Instead of requiring a human to manually sort through this data, the platform uses advanced algorithms to Discover your landscape, Analyze patterns of behavior, and Automate the response to any deviations from the norm. It essentially acts as a digital nervous system for your IT operations.
Transitioning to an AIOps model with a boutique partner like Aloha Clouds shifts your team from a reactive “firefighting” mode to a proactive, strategic stance. Key benefits include:
Reduced MTTR (Mean Time to Repair): By identifying root causes automatically, teams resolve incidents up to 50% faster.
Operational Calm: Eliminates the stress of “alert fatigue” by surfacing only the issues that truly matter.
Cost Efficiency: Automating routine remediations reduces the overhead costs of manual 24/7 monitoring.
Improved Employee Experience: IT teams can stop performing repetitive manual tasks and focus on high-value innovation and platform evolution.
In a traditional setup, a single server failure can trigger hundreds of individual alerts, overwhelming your Service Desk. AIOps solves this through Event Correlation.
The platform analyzes the relationships between these alerts in real-time. It recognizes that 200 different “warning” signals are actually all stemming from a single database issue. It then groups those 200 alerts into one single, actionable Incident. This process quiets the operational noise, allowing your senior architects to see the “signal” and act with precision.
Yes. This is the core of Predictive Intelligence. Unlike traditional monitoring which triggers an alarm after a threshold is crossed, AIOps uses Anomaly Detection.
It learns the “baseline” of your unique environment. If a specific application starts consuming 5% more memory every hour, a trend that wouldn’t normally trigger a standard alert, AIOps identifies this as a suspicious pattern. It can then flag the risk or trigger an automated fix (like scaling resources) before the system actually crashes, ensuring a truly hassle-free experience for your users.
Think of traditional ITOM (IT Operations Management) as the foundation and AIOps as the intelligence built upon it.
Traditional ITOM is about visibility and mapping. It tells you what assets you have (CMDB) and notifies you when something is “Up” or “Down” based on static rules. It requires heavy manual intervention to decide what to do next.
AIOps adds the “brain.” It uses the data collected by ITOM but applies machine learning to understand why things are happening and how to fix them automatically.
While ITOM gives you a map of your infrastructure, AIOps provides the autopilot that navigates through incidents autonomously.


